4.3 知识蒸馏¶
学习目标
- 理解什么是模型的知识蒸馏.

1.什么是模型蒸馏¶
在工业级的应用中, 除了要求模型要有好的预测效果之外, 往往还希望它的"消耗"足够小. 也就是说一般希望部署在线上的应用模型消耗较小的资源. 这些资源包括存储空间, 包括算力.
在深度学习背景下, 如果希望模型的效果足够好, 通常会有两种方案:
- 使用更大规模的参数.
- 使用集成模型, 将多个弱模型集成起来.
注意: 上面两种方案往往需要较大的计算资源, 对部署非常不利. 由此产生了模型压缩的动机: 我们希望有一个小模型, 但又能达到大模型一样或相当的效果.
模型蒸馏是一种通过将一个复杂模型(教师模型)的知识转移给一个简单模型(学生模型)的方法,以提高学生模型的性能。在减小模型体积的同时,保持或提升模型性能。
- 知识蒸馏的概念最早由Hinton在2015年提出, 在2019年后火热起来.
- 知识蒸馏在目前已经成为一种既前沿又常用的提高模型泛化能力和部署优势的方法.
2.知识蒸馏的原理和算法¶
知识蒸馏的核心是有两个模型,一个教师模型,一个是学生模型。
2.1 教师模型¶
- 定义: 复杂的、高性能的模型,通常是大型深度神经网络。
- 特点: 参数量大,能够学习复杂的特征和关系。
2.2 学生模型¶
- 定义: 简化的、小型的模型。
- 特点: 参数量较小,适用于资源受限的场景。
2.3知识蒸馏架构¶
教师模型:需要提前训练好,教师模型往往模型规模较大,模型较为复杂。
学生模型:可以不需要提前训练好,学生模型往往模型规模较小,模型较为简单。
思考:
学生模型可以学习教师模型哪些内容呢?
学生模型的Loss从哪里来?

目前主要两种蒸馏方式:
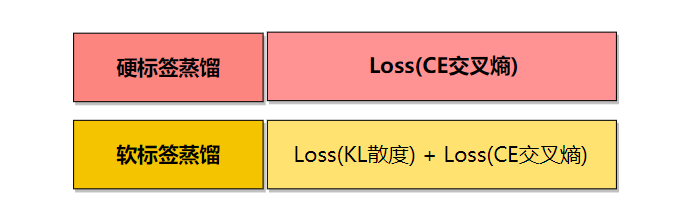
① 硬标签
学生模型直接学习教师模型硬标签,即教师模型预测的具体类别作为学生的label。
② 软标签蒸馏
学生模型学习教师模型的硬标签和教师模型软标签,将两种losss进行相加来更新学生模型的参数。
着重介绍一下软标签蒸馏:
我们对知识蒸馏进行公式化处理: 先训练好一个精度较高的Teacher网络(一般是复杂度较高的大规模预训练模型), 然后将Teacher网络的预测结果q作为Student网络的"学习目标", 来训练Student网络(一般是速度较快的小规模模型), 最终使得Student网络的结果p接近于q. 损失函数如下:
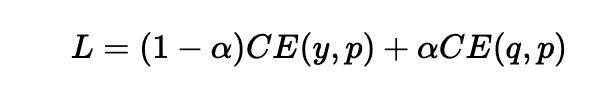
- 上式中CE是交叉熵(Cross Entropy), y是真实标签, q是Teacher网络的输出结果, p是Student网络的输出结果.
原始论文中提出了softmax-T公式:
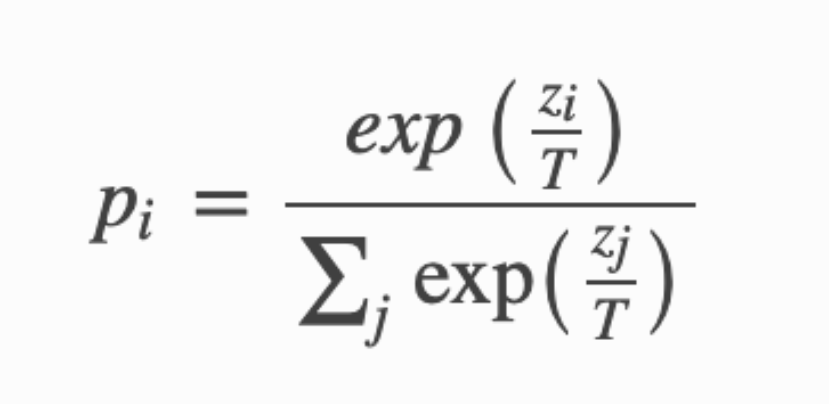
上式中 \(pi\) 是Student网络学习的对象, 也就是所谓的软标签(soft targets), \(zi\) 是神经网络 softmax 前的输出logits.
不同的温度系数T值, 对softmax-T算法有不同的影响, 总结如下:
- 如果将T值取1, softmax-T公式就成为softmax公式, 根据logits输出各个类别的概率.
- 如果T越接近于0, 则最大值会越接近1, 其他值会接近0, 类似于退化成one-hot编码.
- 如果T越大, 则输出的结果分布越平缓, 相当于标签平滑的原理, 起到保留相似信息的作用.
- 如果T趋于无穷大, 则演变成均匀分布.
3.代码实现¶
以下是模型蒸馏的基本训练步骤:
- 准备教师模型(bert大模型): 使用一个较大的模型进行训练, 这个模型在任务上表现很好。
- 使用教师模型生成软目标: 对训练数据集进行推理,得到教师模型的输出概率分布(软目标)。这些概率分布包含了模型对每个类别的置信度信息。
- 准备学生模型(BiLSTM小模型): 初始化一个较小的模型,这是我们要训练的目标模型。
- 使用软目标和硬标签进行训练: 使用原始的硬标签(实际标签)和教师模型生成的软目标来训练学生模型。损失函数由两部分组成:
- 硬标签损失(通常为交叉熵损失): 学生模型的输出与实际标签之间的差距。
- 软目标损失: 学生模型的输出与教师模型生成的软目标之间的差距。这通常使用 KL 散度(Kullback-Leibler Divergence)来度量。
- 调整温度参数: KL 散度的计算涉及一个温度参数,该参数可以调整软目标的分布。温度较高会使分布更加平滑。在训练过程中,可以逐渐降低温度以提高蒸馏效果。
代码位置:

3.1 config配置文件实现¶
代码位置:
以下是config配置文件:
import torch
import os
import datetime
from transformers.models import BertModel,BertTokenizer,BertConfig
current_date=datetime.datetime.now().date().strftime("%Y%m%d")
class Config(object):
def __init__(self):
"""
配置类,包含模型和训练所需的各种参数。
"""
self.model_name = "bert" # 模型名称
self.data_path = "../../01-data" #数据集的根路径
self.train_path = self.data_path + "\\train.txt" # 训练集
self.dev_path = self.data_path + "\\dev3.txt" # 少量验证集,快速验证
# self.dev_path = self.data_path + "\\dev.txt" # 全量验证集
self.test_path = self.data_path + "\\test.txt" # 测试集
self.class_num = len([line.strip() for line in open("../../01-data/class.txt",encoding="utf-8")]) # 类别名单
# BERT原模型训练结果保存路径
self.model_save_dir = "../../04-bert/save_models"
if not os.path.exists(self.model_save_dir):
os.mkdir(self.model_save_dir)
self.model_save_path = self.model_save_dir +"\\bert20250521.pt"
# BERT蒸馏模型存储结果路径
self.distil_model_save_dir = "./models_save"
if not os.path.exists(self.distil_model_save_dir):
os.mkdir(self.distil_model_save_dir)
self.distil_h_model_save_path = self.distil_model_save_dir + "\\student_distll_h.pt"
self.distil_s_model_save_path = self.distil_model_save_dir + "\\student_distll_s.pt"
# 模型训练+预测的时候, 放开下一行代码, 在GPU上运行.
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.num_epochs = 2 # epoch数
self.batch_size = 2 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = "../../04-bert/bert-base-chinese" # 预训练BERT模型的路径
self.bert_model=BertModel.from_pretrained(self.bert_path)
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path) # BERT模型的分词器
self.bert_config = BertConfig.from_pretrained(self.bert_path) # BERT模型的配置
self.hidden_size = 768 # BERT模型的隐藏层大小
# BiLSTM模型参数配置
# self.embed_size = 128
# self.hidden_size_lstm = 256
# self.num_layers = 2
# self.dropout = 0.3
# self.save_model_path = "./models_save"
# self.dropout=0.3
self.embed_size = 256
self.hidden_size_lstm = 512
self.num_layers = 4
self.dropout = 0.3
self.save_model_path = "./models_save"
self.dropout=0.3
if __name__ == '__main__':
conf = Config()
print(conf.bert_config)
input_size=conf.tokenizer.convert_tokens_to_ids(["你", "好", "中国人"])
print(input_size)
3.2 教师模型¶
代码位置:
基于本之前的bert_classifer_model一致,只是调整forward返回值部分,增加pool层输出:
(1)导入依赖包¶
import torch
import torch.nn as nn
from transformers import BertModel
from config import Config
from utils import build_dataloader
(2)BertClassifier类¶
class BertClassifier(nn.Module):
"""
BERT + 全连接层的分类模型。
"""
def __init__(self):
"""
初始化模型,包括BERT和全连接层。
"""
super(BertClassifier, self).__init__()
# 加载预训练的BERT模型
self.bert = BertModel.from_pretrained(conf.bert_path)
# 全连接层:将BERT的隐藏状态映射到类别数
self.fc = nn.Linear(conf.hidden_size, conf.num_classes)
def forward(self, input_ids, attention_mask, return_hidden=False):
# x: 模型输入,包含句子、句子长度和填充掩码。
# _是占位符,接收模型的所有输出,而 pooled 是池化的结果,将整个句子的信息压缩成一个固定长度的向量
_, pooled = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)
# 模型输出,用于文本分类
out = self.fc(pooled)
if return_hidden:
return out, pooled # 返回logits和隐藏状态
return out
(3)主函数(测试)¶
if __name__ == '__main__':
# 1.加载配置文件
conf = Config()
# 2.实例化模型
model = BertClassifier()
# 3.加载数据
train_dataloader,test_dataloader,dev_dataloader=build_dataloader()
# 4.遍历批次,模型预测
for batch in train_dataloader:
input_ids, attention_mask, labels = batch
logits = model(input_ids, attention_mask)
print(logits.shape)
print(torch.argmax(logits, dim=1))
print(labels)
3.3 学生模型¶
代码位置:
(1)导入依赖包¶
(2)BiLSTM类¶
class BiLSTMClassifier(nn.Module):
"""
BiLSTM + 全连接层的分类模型,作为学生模型。
"""
def __init__(self, embed_size=128, hidden_size=256, num_layers=2, num_classes=conf.num_classes, dropout=0.3):
"""
初始化BiLSTM模型。
参数:
embed_size: 嵌入维度。
hidden_size: LSTM隐藏状态维度。
num_layers: LSTM层数。
num_classes: 分类类别数。
dropout: Dropout比例。
"""
super(BiLSTMClassifier, self).__init__()
vocab_size = conf.tokenizer.vocab_size # 从BERT分词器动态获取词汇表大小
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, bidirectional=True, batch_first=True, dropout=dropout)
self.hidden_projection = nn.Linear(hidden_size * 2, conf.hidden_size) # 映射到BERT隐藏状态维度
self.fc = nn.Linear(hidden_size * 2, num_classes)
self.dropout = nn.Dropout(dropout)
def forward(self, input_ids, attention_mask, return_hidden=False):
"""
前向传播,仅在嵌入层使用 attention_mask 进行掩码处理。
参数:
input_ids: 输入的token ID,形状为 [batch_size, seq_len]。
attention_mask: 注意力掩码,形状为 [batch_size, seq_len],1 表示有效 token,0 表示填充 token。
return_hidden: 是否返回隐藏状态。
返回:
logits: 分类logits,形状为 [batch_size, num_classes]。
hidden: 最后一时间步的隐藏状态(若 return_hidden=True),形状为 [batch_size, hidden_size*2]。
"""
# 嵌入层
embed = self.embedding(input_ids) # [batch_size, seq_len, embed_size]
# 使用 attention_mask 掩码填充 token 的嵌入(核心处理)
attention_mask = attention_mask.unsqueeze(-1) # [batch_size, seq_len, 1]
embed = embed * attention_mask # 将填充 token 的嵌入置为 0
# LSTM 层
lstm_out, (hidden, _) = self.lstm(embed) # lstm_out: [batch_size, seq_len, hidden_size*2]
# 取最后一时间步的隐藏状态(填充 token 已置 0,无需再次处理)
hidden = lstm_out[:, -1, :] # [batch_size, hidden_size*2]
# Dropout 和全连接层
hidden = self.dropout(hidden) # [batch_size, hidden_size*2]
logits = self.fc(hidden) # [batch_size, num_classes]
if return_hidden:
projected_hidden = self.hidden_projection(hidden) # 映射到768维
return logits, projected_hidden
return logits
(3)主函数(测试)¶
if __name__ == '__main__':
# 1.加载配置文件
conf = Config()
# 2.实例化学生模型
model = BiLSTMClassifier(conf)
# 3.加载数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
print(model)
# 4.遍历批次,模型预测
for batch in train_dataloader:
input_ids, attention_mask, labels = batch
logits = model(input_ids, attention_mask)
print(f"Logits shape: {logits}")
3.4 硬标签蒸馏¶
代码位置:
导包以及配置:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import AdamW
from sklearn.metrics import classification_report, f1_score, accuracy_score, precision_score
from tqdm import tqdm
from utils import build_dataloader, get_time_diff
from bert_classifer_model import BertClassifier
from bilstm_classifier import BiLSTMClassifier
from config import Config
import time
以下是训练代码逻辑,核心区别仅仅是在loss计算上:
(1)model2train¶
def model2train(teacher_model, student_model, train_loader, dev_loader):
"""
训练学生模型(BiLSTM)使用硬标签蒸馏,学习教师模型(BERT)的预测类别。
参数:
teacher_model: 教师模型(BERT),提供硬标签。
student_model: 学生模型(BiLSTM),需要学习教师模型的预测。
train_loader: 训练数据加载器,提供训练数据批次。
dev_loader: 验证数据加载器,提供验证数据批次。
"""
# 初始化参数
best_dev_f1 = 0.0 # 记录最佳验证 F1 分数
step = 0 # 训练步数计数器
patience = 3 # 早停耐心值
epochs_no_improve = 0 # 记录未提升的 epoch 数
# 1.初始化优化器和损失函数
optimizer = AdamW(student_model.parameters(), lr=conf.learning_rate) # 使用 AdamW 优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于硬标签损失
# 2.1 遍历每个epoch
for epoch in range(conf.num_epochs):
student_model.train() # 设置学生模型为训练模式
teacher_model.eval() # 设置教师模型为评估模式(不更新权重)
total_loss = 0 # 记录当前 epoch 的总损失
train_preds, train_labels = [], [] # 记录训练预测和真实标签
epoch_start_time = time.time() # 记录 epoch 开始时间
print(f"\n硬标签蒸馏训练 Hard Label Distillation Epoch {epoch + 1}/{conf.num_epochs}...")
# 2.2 遍历训练数据批次
for batch in tqdm(train_loader, desc=f"Hard Label Distillation Epoch {epoch + 1}/{conf.num_epochs}"):
step_start_time = time.time() # 记录当前 step 开始时间
input_ids, attention_mask, labels = batch # 获取输入数据
input_ids, attention_mask, labels = input_ids.to(conf.device), attention_mask.to(conf.device), labels.to(conf.device)
# 3.1.1 获取教师模型的预测(硬标签)
with torch.no_grad():
teacher_logits = teacher_model(input_ids, attention_mask)
teacher_preds = torch.argmax(teacher_logits, dim=1)
# 3.1.2 获取学生模型的输出 logits
student_logits = student_model(input_ids, attention_mask)
# 3.2 计算硬标签损失(交叉熵,使用教师模型的预测)
loss = criterion(student_logits, teacher_preds)
# 3.3 梯度归零
optimizer.zero_grad()
# 3.4 反向传播
loss.backward()
# 3.5 参数更新
optimizer.step()
total_loss += loss.item() # 累加损失
# 4.记录预测结果
preds = torch.argmax(student_logits, dim=1)
train_preds.extend(preds.cpu().numpy())
train_labels.extend(labels.cpu().numpy())
step += 1 # 步数加 1
step_duration = time.time() - step_start_time # 计算 step 耗时
# 5.每 10 个 step 验证一次
if step % 10 == 0:
student_model.eval() # 切换到评估模式
avg_loss = total_loss / (len(train_preds) / train_loader.batch_size) # 计算平均损失
report, f1score, accuracy, precision = model2dev(student_model, dev_loader, conf.device) # 验证
print(f"Step {step}, Epoch {epoch + 1}/{conf.num_epochs}")
print(f"Step Duration: {step_duration:.2f}s")
print(f"Train Loss: {avg_loss:.4f}")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
# 6.1 计算训练集指标
train_report = classification_report(train_labels, train_preds)
# 6.2 验证(每个 epoch 结束时)
student_model.eval()
report, f1score, accuracy, precision = model2dev(student_model, dev_loader, conf.device)
# 7.计算 epoch 耗时
epoch_duration = time.time() - epoch_start_time
print(f"\nEpoch {epoch + 1}/{conf.num_epochs}")
print(f"Epoch Duration: {epoch_duration:.2f} seconds")
print(f"Train Loss: {total_loss / len(train_loader):.4f}")
print(f"Train 分类报告: {train_report}")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
# 8.保存最佳模型并检查早停
if f1score > best_dev_f1:
best_dev_f1 = f1score
torch.save(student_model.state_dict(), conf.distil_h_model_save_path)
print("模型保存!!")
epochs_no_improve = 0
else:
epochs_no_improve += 1
print(f"Dev F1 未提升,当前未提升 epoch 数: {epochs_no_improve}/{patience}")
if epochs_no_improve >= patience:
print(f"早停触发!Dev F1 在 {patience} 个 epoch 内未提升,停止训练。")
break
student_model.train()
(2)model2dev¶
def model2dev(model, data_loader, device):
model.eval()
preds, true_labels = [], []
# 1.关闭梯度计算
with torch.no_grad():
# 2.遍历数据
for batch in tqdm(data_loader, desc="BiLSTM Classifier Evaluating ......"):
input_ids, attention_mask, labels = batch
input_ids, attention_mask, labels = input_ids.to(device), attention_mask.to(device), labels.to(device)
# 3.前向传播
logits = model(input_ids, attention_mask)
# 4.获取模型输出 logits
batch_preds = torch.argmax(logits, dim=1)
# 收集预测和真实标签
preds.extend(batch_preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
# 计算分类报告和指标
report = classification_report(true_labels, preds)
f1score = f1_score(true_labels, preds, average='micro')
accuracy = accuracy_score(true_labels, preds)
precision = precision_score(true_labels, preds, average='micro')
return report, f1score, accuracy, precision
(3)主函数¶
if __name__ == '__main__':
# 记录训练开始时间
start_time = time.time()
# 1.加载配置文件
conf = Config() # 加载配置文件
# 2.加载教师训练数据与学生训练数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 3.定义教师模型,加载模型参数
teacher_model = BertClassifier().to(conf.device)
teacher_model.load_state_dict(torch.load(conf.model_save_path, map_location=conf.device))
# 4.定义学生模型
student_model = BiLSTMClassifier(conf).to(conf.device)
# 5.模型训练
model2train(teacher_model, student_model, train_dataloader, dev_dataloader)
# 6.获取训练耗时
total_training_duration = get_time_diff(start_time)
print(f"硬标签蒸馏训练耗时: {total_training_duration}")
3.5 软标签蒸馏¶
代码位置:
导包以及相关配置文件:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import AdamW
from tqdm import tqdm
from config import Config
from utils import build_dataloader, get_time_diff
from bert_classifer_model import BertClassifier
from bilstm_classifier import BiLSTMClassifier
import time
from hard_label_distillation import model2dev
以下是训练代码逻辑,核心区别仅仅是在loss计算上:
(1)model2train¶
def model2train():
# 配置参数信息
T = 2.0 # 温度参数,用于软标签蒸馏
alpha = 0.7 # 软标签和硬标签损失的权重
step = 0 # 训练步数计数器
best_dev_f1 = 0.0 # 记录最佳验证 F1 分数
# 1.教师训练数据与学生训练数据
train_dataloader, test_dataloader, dev_dataloader = build_dataloader()
# 2.定义教师模型,加载模型参数
teacher_model = BertClassifier().to(conf.device)
teacher_model.load_state_dict(torch.load(conf.model_save_path, map_location=conf.device))
# 3.定义学生模型
student_model = BiLSTMClassifier(conf).to(conf.device)
# 4.初始化优化器和损失函数
optimizer = AdamW(student_model.parameters(), lr=conf.learning_rate) # 使用 AdamW 优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,用于硬标签损失
# 5.1 遍历每个 epoch
for epoch in range(conf.num_epochs):
## 设置学生模型为训练模式,设置教师模型为评估模式(不更新权重)
student_model.train()
teacher_model.eval()
# 5.2 遍历训练数据批次
for batch_index, (input_ids, attention_mask, labels) in enumerate(
tqdm(train_dataloader, desc=f"软标签蒸馏训练的 Epoch {epoch + 1}/{conf.num_epochs}")):
# 6. input_ids, attention_mask, label放到设备
input_ids, attention_mask, labels = input_ids.to(conf.device), attention_mask.to(conf.device), labels.to(conf.device)
# 6.1.1 获取教师模型的输出 logits软标签与教师模型的硬标签
with torch.no_grad():
teacher_logits = teacher_model(input_ids, attention_mask)
teacher_preds = torch.argmax(teacher_logits, dim=1) # 获取教师模型的硬标签
# 6.1.2 获取学生模型的输出 logits
student_logits = student_model(input_ids, attention_mask)
# 6.2.1 计算软标签损失(KL 散度)
teacher_log_probs = F.softmax(teacher_logits / T, dim=1) # 教师模型的 概率
student_log_probs = F.log_softmax(student_logits / T,dim=1) # 学生模型的 log-概率
soft_loss = F.kl_div(student_log_probs, teacher_log_probs, log_target=True, reduction='batchmean') * (T * T) # 论文 softmax-T 预测值和真实值相差1/(T*T)
# 6.2.2 计算硬标签损失(交叉熵,使用教师模型的预测)
hard_loss = criterion(student_logits, teacher_preds)
# 6.2.3 总损失:软标签和硬标签损失的加权和
loss = alpha * soft_loss + (1 - alpha) * hard_loss
# 6.3 梯度归零
optimizer.zero_grad()
# 6.4 反向传播
loss.backward() # 反向传播计算梯度
# 6.5 参数更新
optimizer.step()
# 7. 每 2 个 batch 验证一次,batch级别验证model2dev
if batch_index % 2 == 0:
report, f1score, accuracy, precision = model2dev(student_model, dev_dataloader, conf.device) # 验证
print(f"Step {step}, Epoch {epoch + 1}/{conf.num_epochs} ===============批级别=============")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
if f1score > best_dev_f1:
torch.save(student_model.state_dict(), conf.distil_s_model_save_path)
# 8. epoch级别验证 model2dev
report, f1score, accuracy, precision = model2dev(student_model, dev_dataloader, conf.device)
print(f"\nEpoch {epoch + 1}/{conf.num_epochs}==============================epoch级别===========")
print(f"Dev F1: {f1score:.4f}, Dev Accuracy: {accuracy:.4f}")
print(f"Dev Precision: {precision:.4f}")
print(f"Dev 分类报告:\n{report}")
student_model.train() # 切换回训练模式
(2)model2dev¶
(3)主函数¶
if __name__ == "__main__":
# 主程序:加载数据和模型,开始训练
start_time = time.time() # 记录训练开始时间
# 1.加载配置文件
conf = Config()
# 2.模型训练
model2train()
# 3.训练总耗时
total_training_duration = get_time_diff(start_time) # 计算总训练耗时
print(f"软标签蒸馏训练耗时: {total_training_duration}")
日志打印:
Dev F1: 0.89.89, Dev Accuracy: 0.89.89
Dev Precision: 0.89.89
Dev Classification Report:
precision recall f1-score support
0 0.94 0.83 0.88 58
1 0.95 0.82 0.88 50
2 0.80 0.83 0.81 52
3 0.96 0.94 0.95 51
4 0.73 0.85 0.79 48
5 0.85 0.80 0.82 44
6 0.86 0.89 0.87 61
7 0.93 0.95 0.94 44
8 0.93 0.90 0.91 48
9 0.82 0.93 0.87 55
accuracy 0.89 511
macro avg 0.89 0.89 0.89 511
weighted avg 0.89 0.89 0.89 511
结论:Teacher模型在测试集上的表现是Test Acc: 93.64%,Student模型在测试集上的表现是Test Acc: 89.89%,
- 1、模型大小明显减少
- BERT模型390MB, 最优的BiLSTM模型104MB
-
模型大小压缩为原来的26.7%
-
2、模型在测试集上准确率仅有2.39%的下降
- BERT模型准确率93.64%
- BiLSTM模型知识蒸馏后30个epochs准确率91.25%
3.6 预测脚本¶
代码位置:
以下是对通过中间蒸馏方式得到的BiLSTM模型:
(1)导入依赖包¶
(2)获取类别列表¶
(3)预测函数predict¶
# 预测函数
def predict(data):
# 处理输入数据 data["text"]
text = data["text"]
if not text.strip():
return {"text": text, "pred_class": None}
# 分词并编码,使用 tokenizer.encode_plus,返回 PyTorch 张量
encoded = conf.tokenizer.encode_plus(text, return_tensors="pt")
# 获取 input_ids 和 attention_mask
input_ids = encoded["input_ids"].to(conf.device)
attention_mask = encoded["attention_mask"].to(conf.device)
# 开启模型推理模式
with torch.no_grad():
# 开始时间
start_time = time.time()
# 模型预测
logits = model(input_ids, attention_mask)
# 获取最大 logits 的索引
pred_idx = torch.argmax(logits, dim=1).item()
# 获取预测的类别
pred_class = class_list[pred_idx]
# 预测时间
elaspe_time = (time.time()-start_time)*1000
return text, pred_class, elaspe_time
(4)主函数¶
if __name__ == "__main__":
# 1.初始化配置
conf = Config()
# 2.实例化 BiLSTM 模型
model = BiLSTMClassifier(conf).to(conf.device)
# 3.加载预训练模型权重(需替换为实际路径)
model.load_state_dict(torch.load(conf.distil_s_model_save_path)) # 软标签蒸馏模型
# model.load_state_dict(torch.load(conf.distil_h_model_save_path)) # 硬标签蒸馏模型
model.eval()
# 测试输入
sample_data = {"text": "中华女子学院:本科层次仅1专业招男生"}
text, pred_class, elaspe_time = predict(sample_data)
print(f"预测结果:{pred_class}")
print(f"预测耗时:{elaspe_time}ms")
4.本节小结¶
- 本小节主要介绍了模型蒸馏,实现蒸馏的方式。
- 通过代码实现2种模型蒸馏。