3.4 大模型LLM¶
学习目标:
1.了解什么是大模型LLM
2.大模型应用方式
3.大模型实现投满分分类
(一) 关于大模型LLM¶
1.1 什么是LLM¶
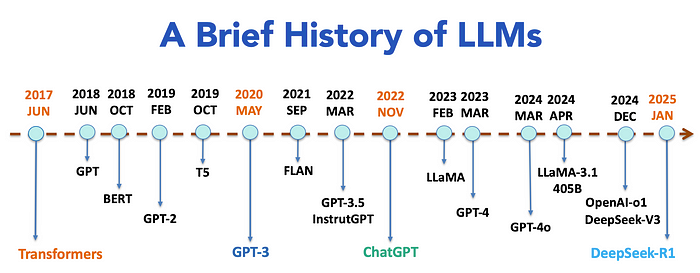
LLM即为Large Language Model英文的简写,译为大语言模型。LLM通常都是具有大规模参数(通常在十亿到万亿级别)的深度学习模型。这类模型通过在大规模数据集上进行训练,具备强大的泛化能力和复杂的任务处理能力,尤其在自然语言处理(NLP)、计算机视觉(CV)和多模态任务中表现突出。例如,GPT-3(1750亿参数)
- 模型单位:
在使用大模型时,经常看到B或者M单位的模型,或者是它的上下文长度为多少k,下面是对这些常见单位量级的理解:
K(Kilo, 千):表示 1k=1,000。在机器学习模型中,通常用来描述较小模型的参数量,比如 100K(十万)参数。
M(Million, 百万):表示 1M=1,000,000。一般用于中等规模的模型,比如 BERT-base(110M)。110M = 110 × 100 万 = 1.1 亿
B(Billion, 十亿):表示 1B= 1,000,000,000。大型模型通常达到这一量级,比如 GPT-3(175B)。
T(Trillion, 万亿):表示 IT=1,000,000,000,000。这代表非常巨大的参数量。GPT-4(约1.76T)的一些版本和其他超大规模模型已经达到甚至超过 1T 参数。
- 大模型训练硬件:
GPU:被广泛用于AI训练,因为它特别擅长并行计算(同时处理很多小任务)。代表性企业英伟达(NVIDIA),例如显卡A100的40G显存等。
TPU是谷歌专门为AI设计的芯片,比GPU更专注于深度学习任务,特别是张量运算(AI模型里的核心计算)。例如TPU V3的32G显存。
1.2 关于DeepSeek¶
本次用投满分项目分类,我们采用DeepSeek V3–0324模型,进行新闻文本分类。所以我们先整体了解一下DeepSeek。
DeepSeek公司简介(来自官网):
深度求索(DeepSeek),总部在杭州,成立于2023年,专注于研究世界领先的通用人工智能底层模型与技术,挑战人工智能前沿性难题。基于自研训练框架、自建智算集群和万卡算力等资源,深度求索团队仅用半年时间便已发布并开源多个百亿级参数大模型,如DeepSeek-LLM通用大语言模型、DeepSeek-Coder代码大模型,并在2024年1月率先开源国内首个MoE大模型(DeepSeek-MoE),各大模型在公开评测榜单及真实样本外的泛化效果均有超越同级别模型的出色表现。
注意:DeepSeek在以远低于 OpenAI 的 o1 的成本,开发了 DeepSeek-R1 后获得了国际关注。DeepSeek V3–0324 是对前代 DeepSeek V3(于2023年12月24日发布) 的一次重要更新。
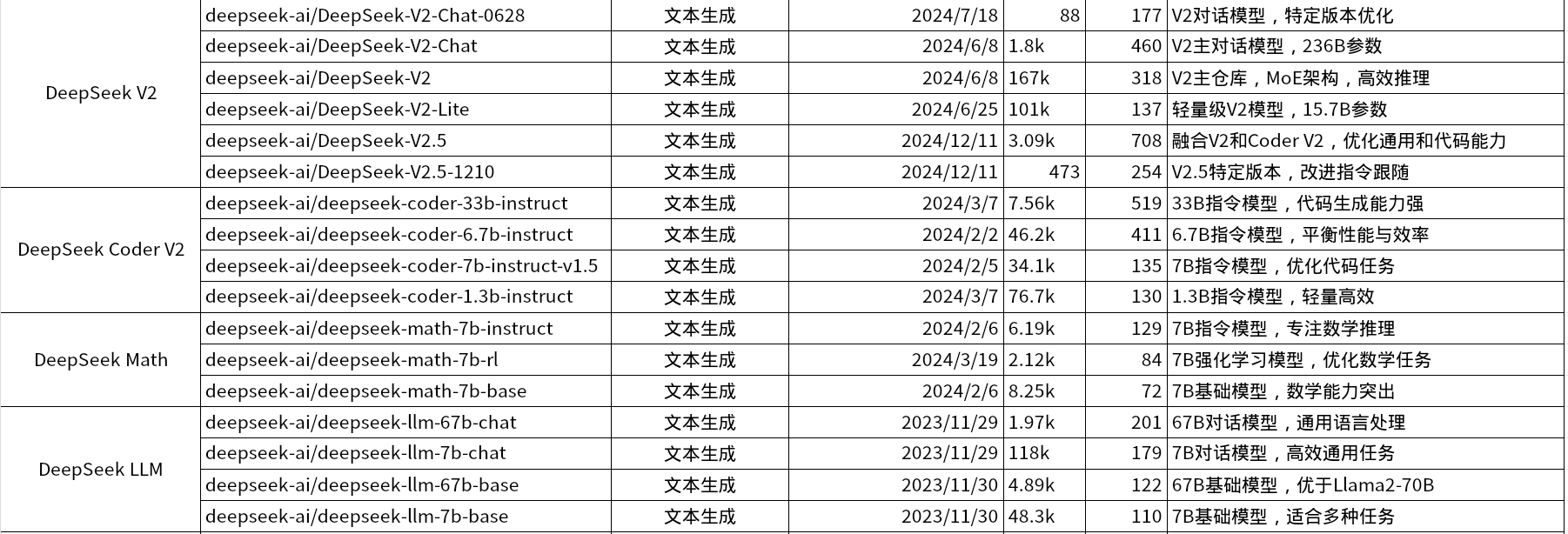
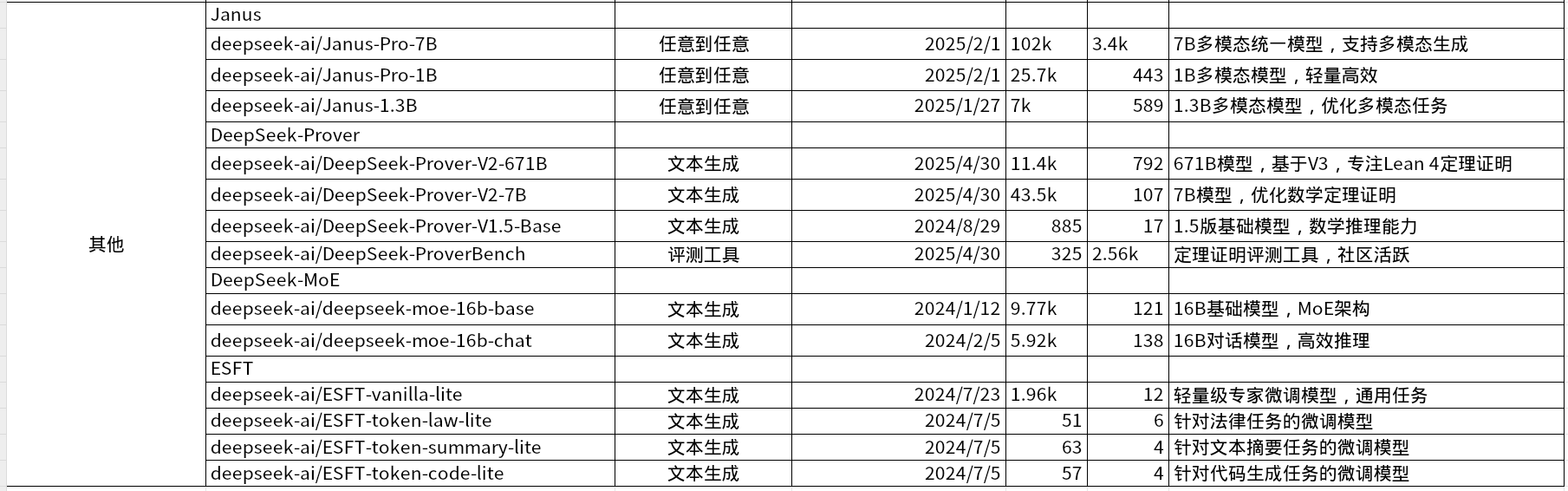
DeepSeek模型列表
deepseek目前拥有较多系列的模型,以下为可下载的开源模型列表: 开源模型下载地址:https://huggingface.co/deepseek-ai

关于DeepSeek V3 与 DeepSeek R1:
DeepSeek-V3 :
我们与 DeepSeek 交互时使用的默认模型。它是一个多功能的大型语言模型 (LLM),作为可以处理各种任务的通用工具脱颖而出。类似chatgpt一样,可以直接提问并解决通用的一些问题。
DeepSeek-R1:
DeepSeek-R1是一个强大的推理模型,专为解决需要高级推理和深入解决问题的任务而构建。它的与众不同之处在于它对强化学习的特殊使用。为了训练 R1,DeepSeek 建立在 V3 奠定的基础之上,利用其广泛的能力和较大的参数空间。他们通过允许模型为解决问题的场景生成各种解决方案来执行强化学习。然后使用基于规则的奖励系统来评估答案和推理步骤的正确性。这种强化学习方法鼓励模型随着时间的推移完善其推理能力,有效地学习自主探索和开发推理路径。

DeepSeek-V3与DeepSeek-R1比较:
以下表格比较DeepSeek-V3和DeepSeek-R1在推理能力、响应速度和上下文处理上的表现,直接描述两者的优劣势,基于技术特点和通用表现,可以快速了解适用场景。
特性 DeepSeek-V3 DeepSeek-R1 解释 推理能力 依赖“下一词预测”,适合简单任务,不擅长复杂推理 通过强化学习和思维链推理,擅长复杂问题解决 V3像会背书的学霸,知识多但不擅长原创思考;R1像逻辑严密的科学家,能推导新答案。适合简单问答用V3,复杂逻辑用R1。 响应速度 MoE架构,响应几乎即时 因推理耗时,响应较慢 V3像快餐店,快速出餐,适合实时需求;R1像大厨,精心烹饪但耗时长。适合快速回答用V3,深入分析用R1。 上下文处理 支持64,000字符,适合短对话 支持64,000字符,擅长复杂长对话 V3像朋友间随便聊聊,适合短对话;R1像开会追踪话题,适合长篇讨论。适合简单问答用V3,研究讨论用R1。
1.3 DeepSeek V3大模型使用¶
通常我们实际工作中主要有以下三种使用方式,作为开发人员用的最多的是第②种和第③种。本次基于投满分项目使用的deepseek模型采用的是方式②,即官方的API进行新闻文本分类。所以需要大家到官方网站申请API key。
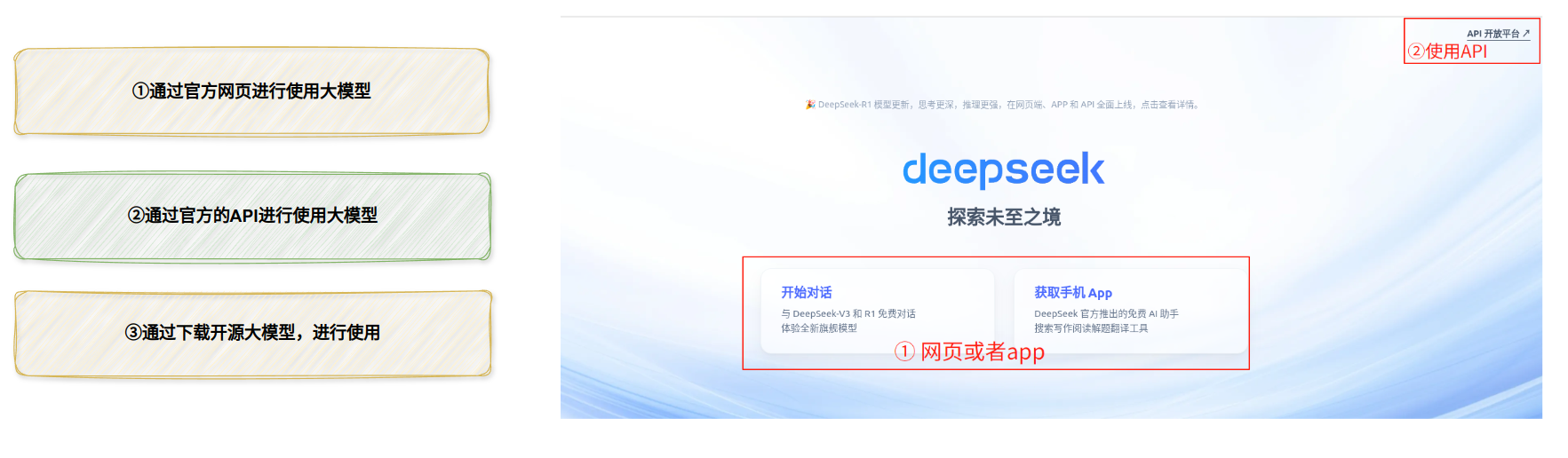
DeepSeek V3–0324 大模型使用:
① 开源地址自己部署:
DeepSeek-V3-0324 与之前的 DeepSeek-V3 使用同样的 base 模型,仅改进了后训练方法。模型参数约 660B,开源版本上下文长度为 128K(网页端、App 和 API 提供 64K 上下文)。V3-0324 模型权重下载请参考:
Model Scope: https://modelscope.cn/models/deepseek-ai/DeepSeek-V3-0324
Huggingface: https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
② DeepSeek的在线API key申请
什么是API key?
API Key(应用程序接口密钥)是一种用于身份验证的唯一标识符,通常是一串由字母、数字或符号组成的代码。API Key 确保只有授权的用户或应用程序能够调用大模型的服务,同时帮助服务提供商跟踪使用情况、限制访问权限、防止滥用,并可用于计费或配额等管理。
API Key 就像是你在网上点外卖时用的“专属取餐码”。它就是你和大模型之间的“通行证”!
API key申请:
https://platform.deepseek.com/sign_in https://api-docs.deepseek.com/zh-cn/news/news250325
(二) 代码结构图¶

DeepSeek实现投满分新闻分类:
- .env文件:主要用于存放我们的api key信息,类似配置文件。
DEEPSEEK_API_KEY=sk-XXXXXXXXXXXXXXXXXXXXXXXXX
base_url=https://api.deepseek.com
class_file=../01-data/class.txt
- deepseek_classifierLLM.py文件是主要的deepseek分类逻辑实现。
代码位置:TMFCode\05-LLM
(三) 原理及代码实现¶
代码逻辑图:
代码位置:
3.1 原理图¶
3.2 快速实操¶
(1)API Key获取¶
1、访问网址:https://platform.deepseek.com/api_keys,创建API Key。

2、输入API key名称,随意起一个即可。

3、点击创建后会出现API key,记住只出现一次,保存好。 API Key:sk-bxxxxxxxxxxxxxxxxxxxxxxxxxxxxx

(2)调用DeepSeek V3¶
如果没有安装openai的库,要先安装一下。使用 pip install openai。
代码中 api_key 记得替换成小伙伴们自己的。
from openai import OpenAI # pip install openai
import os
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"), base_url=os.getenv("base_url"))
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "你是谁"},
],
stream=False
)
print(response.choices[0].message.content)
代码中,{"role": "user", "content": "你是谁"}中的 content 是单轮对话中你的问题。 返回结果:
可以看到已经返回了DeepSeek-V3版本。
(3)提示词模版¶
你是一个优秀的文本分类师,能把给定的用户query划分到正确的类目中。现在请你根据给定信息和要求,为给定用户query,从备选类目中选择最合适的类目。
下面是“参考案例”即被标注的正确结果,可供参考:
文本:中国国家乒乓球队击败日本
类别:体育
备选类目:
finance,realty,stocks,education,science,society,politics,sports,game,entertainment
请注意:
1. 用户query所选类目,仅能在【备选类目】中进行选择,用户query仅属于一个类目。
2. “参考案例”中的内容可供推理分析,可以仿照案例来分析用户query的所选类目。
3. 请仔细比对【备选类目】的概念和用户query的差异。
4. 如果用户query也不属于【备选类目】中给定的类目,或者比较模糊,请选择“拒识”。
5. 请在“文本类别:”后回复结果,不需要说明理由。
类别:
(4)配置文件config¶
# config.py
class Config(object):
def __init__(self):
# 原始数据路径
self.train_datapath = "../01-data/train.txt"
self.test_datapath = "../01-data/test.txt"
self.dev_datapath = "../01-data/dev.txt"
self.class_datapath = "../01-data/class.txt"
if __name__ == '__main__':
conf = Config()
print(conf.train_datapath)
print(conf.test_datapath)
(5)模型预测model2pred¶
import time
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
def model2pred(Text):
client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"), base_url=os.getenv("base_url"))
system_prompt = '''
你是一个优秀的文本分类师,能把给定的用户query划分到正确的类目中。现在请你根据给定信息和要求,为给定用户query,从备选类目中选择最合适的类目。
下面是“参考案例”即被标注的正确结果,可供参考:
文本:中国国家乒乓球队击败日本
类别:sports
备选类目:
finance,realty,stocks,education,science,society,politics,sports,game,entertainment
请注意:
1. 用户query所选类目,仅能在【备选类目】中进行选择,用户query仅属于一个类目。
2. “参考案例”中的内容可供推理分析,可以仿照案例来分析用户query的所选类目。
3. 请仔细比对【备选类目】的概念和用户query的差异。
4. 如果用户query也不属于【备选类目】中给定的类目,或者比较模糊,请选择“拒识”。
5. 请在“文本类别:”后回复结果,不需要说明理由。
类别:
'''
start_time = time.time()
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": Text},
],
stream=False
)
result = response.choices[0].message.content
elapsed_time = (time.time() - start_time) * 1000
return result, elapsed_time
if __name__ == '__main__':
result, elapsed_time = model2pred("今日大A净流入520亿,全市超3500家上涨。")
print(f'*预测类别:{result}')
print(f'*请求耗时:{elapsed_time:.2f}ms')
预测结果:
(5)模型评估model2dev¶
import time
from tqdm import tqdm
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
import warnings
warnings.filterwarnings("ignore")
from config import Config
conf = Config()
# 获取name2id
id2name = {}
with open(conf.class_datapath, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f): # class0 class 1
label = line.strip()
id2name[idx] = label
# print("类别映射:", id2name)
name2id = {v: k for k, v in id2name.items()}
def model2dev(dev_data):
# 1. 初始化列表,存储预测结果和真实标签
preds, true_labels = [], []
start_time = time.time()
# 2. 模型预测
with open(dev_data, 'r', encoding='utf-8') as f:
for line in tqdm(f, desc="数据预测中....."):
# 2.1 提取批次数据并移动到设备
text, label = line.strip().split('\t')
# 2.2 前向传播:模型预测
result, _ = model2pred(text)
pred = name2id[result]
# 2.3 存储预测和真实标签
preds.append(int(pred))
true_labels.append(int(label))
# 3. 计算分类报告、F1 分数、准确度和精确度
accuracy = accuracy_score(true_labels, preds) # 计算准确度
precision = precision_score(true_labels, preds, average='micro') # 使用微平均计算精确度
f1score = f1_score(true_labels, preds, average='micro') # 使用微平均计算 F1 分数
report = classification_report(true_labels, preds)
elapsed_time = (time.time() - start_time) * 1000
print('预测完成!')
# 4. 返回评估结果
return accuracy, precision, recall_score, f1score, report, elapsed_time
if __name__ == '__main__':
accuracy, precision, recall_score, f1score, report, elapsed_time = model2dev(conf.dev_datapath)
print(f"*准确度:{accuracy}")
print(f"*精确度:{precision}")
print(f"*F1分数:{f1score}")
print(f"*分类报告:{report}")
print(f"*消耗时间:{elapsed_time:.2f}ms")
评估结果:
数据预测中.....: 511it [45:11, 5.31s/it]
预测完成!
*准确度:0.6908023483365949
*精确度:0.6908023483365949
*F1分数:0.6908023483365949
*分类报告: precision recall f1-score support
0 0.54 0.81 0.65 58
1 0.91 0.78 0.84 50
2 0.70 0.37 0.48 52
3 0.93 0.84 0.89 51
4 0.78 0.15 0.25 48
5 0.46 0.75 0.57 44
6 0.62 0.64 0.63 61
7 0.90 0.86 0.88 44
8 0.97 0.71 0.82 48
9 0.62 0.98 0.76 55
accuracy 0.69 511
macro avg 0.74 0.69 0.68 511
weighted avg 0.74 0.69 0.68 511
*消耗时间:2711083.95ms
(四) 本节小结¶
- 本小节主要完成了对大模型基础知识一个学习,以及基于DeepSeek的api方式实现投满分项目分类实现。