4.1 模型压缩概述¶
学习目标:
1.了解什么是模型压缩
2.知道模型压缩的主要四种技术方式
3.知道模型压缩的意义
tips:
在我们前面实际建模以及部署测试过程中,可以发现模型的推理时间相差较大,对于模型参数规模较大且又在资源首先的情况下,如何提升我们的推理时间?这就是本章节主要的目的,即通过模型压缩相关技术来减小模型的大小,在一定程度上对模型准确性上产生不了太大的影响。这种模型规模的减小非常重要,因为较大的 模型很难在资源受限的设备上部署。
所以在本章节中,我们将探讨 3 种流行的模型压缩技术的优缺点。
1.模型压缩背景¶
许多实际应用程序都需要实时的设备上处理功能。例如,家庭安全摄像头上的 AI 必须能够处理是否有不明身份的人试图进入房子并通知您。

目前最在实际使用大模型时候,表现良好的深度学习模型规模较大。但是,模型越大,需要的存储空间就越多,因此很难在资源受限的设备或者业务场景上进行部署或者使用。同时,更大的模型意味着推理时间更长,推理过程中的能耗更高。
所以如何在保证一些模型性能损耗不大的情况下,使得模型尽可能的小,就是我们要解决的问题。而让模型规模变小,我们称之为模型压缩,所以基于上述背景,如何解决大模型在低资源设备硬件上提升推理效率就是模型压缩意义。
2.模型压缩的四种主流技术¶
模型压缩的四种主流技术:
(1)Pruning 剪枝:
剪枝是一种减少深度神经网络参数数量的强大技术。在 深度神经网络中,许多参数是冗余的,因为它们在训练期间贡献不大。因此,在训练之后,可以从网络中删除这些参数,而对准确性的影响很小。
(2)Quantization 量化:
在 深度神经网络模型 中,权重存储为 32 位浮点数,即fp32。量化通过减少每个权重所需的位数来压缩原始网络。例如,权重可以量化为 fp16 位、int8 位甚至 int4 位。通过减少使用的位数,可以显著减小 DNN 的大小,且加速推理速度。
(3)Knowledge distillation 知识蒸馏:
在知识蒸馏中,在大型数据集上训练大型复杂模型。当这个大模型可以泛化并进行推理时,使其知识转移到较小的网络。较大的模型称为教师模型,较小的网络称为学生网络。
(4)Low-rank factorization 低秩因式分解:
低秩因式分解通过采用矩阵分解来识别深度神经网络的冗余参数。当需要减小模型大小时,低秩因式分解技术通过将大型矩阵分解为较小的矩阵来提供帮助。
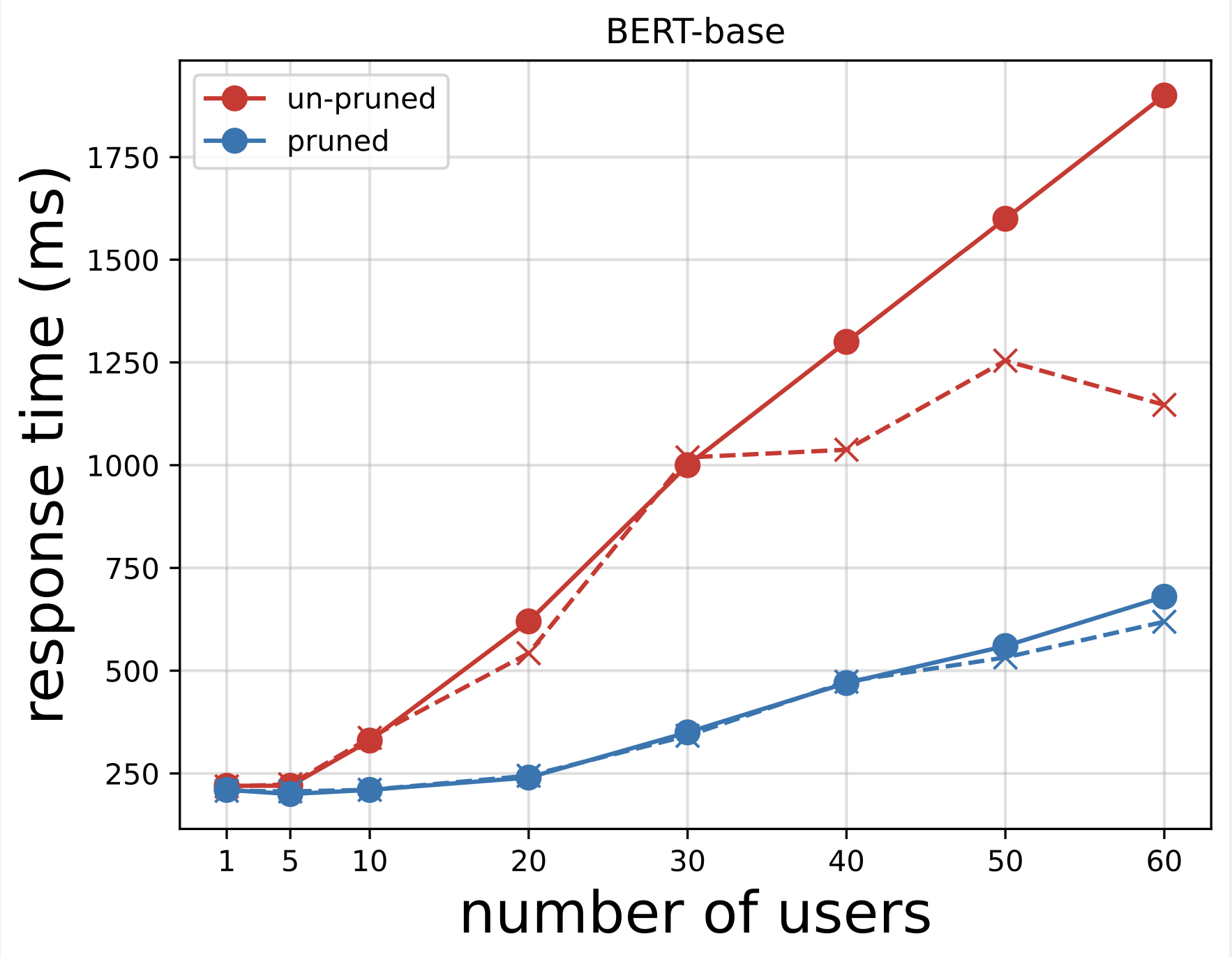
3.模型压缩前后的对比(案例)¶
BERT剪枝前后的推理响应时间:
Llama量化前后的推理响应时间对比:

BERT蒸馏前后的推理、参数对比:
4.本节小结¶
- 本小节主要介绍了模型压缩的背景以及模型压缩的主流方式,模型压缩意义。